数组与切片
因为 切片(slice) 比数组更好用,也跟安全, Go 推荐使用 切片 而不是数组。
# 数组和切片有何异同
Go 语言的 切片 结构的本质是对数组的封装,它描述了一个数组的片段。无论数组还是切片,都可以通过下标来访问单个元素。
数组是定长的,长度定义好后,不能在更改。
在 Go 语言中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 与 [4]int 就是不同的类型。而切片则是非常灵活的,它可以动态地扩容,且切片的类型与长度无关。
func main() {
arr1 := [1]int{1}
arr2 := [2]int{1, 2}
if arr1 == arr2 {
fmt.Println("equal type")
}
}
2
3
4
5
6
7
尝试编译,报错
./slices.go:8:10: invalid operation: arr1 == arr2 (mismatched types [1]int and [2]int)
因为两个数组的长度是不一致的,根本不是一个数据类型,因此也不能比较。
切片实际上是一个结构体,包含三个字段,长度、容量、底层数组。
// gosrc/runtime/slice.go line:13
type slice struct {
array unsafe.Pointer
len int
cap int
}
2
3
4
5
6
底层数组可以被多个切片同时指向,因此对一个切片的元素进行操作有可能影响其他切片。
# 切片如何被截取的
截取也是一种比较常见的创建 slice 的方法,可以从数组或 slice 直接截取,需要指定起始位置。
基于已有 slice 创建新 slice 对象时,新 slice 和老 slice 公用底层数组。新老 slice 对底层数组的更改都会影响到彼此。基于数组创建新 slice 也是同样的效果,对数组或 slice 元素做的更改都会影响到彼此。
新老
slice或 新slice老数组互相影响的前提是两者共用底层数组,如果因为执行append操作使得新slice或老slice底层数组扩容,移动到了新的位置,两者就不会相互影响了。所以,问题的关键在于两者是否共用底层数组。
截取的操作方式如下
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice := data[2:4:6] // data[low, high, max]
2
对 data 使用 3 个索引值,截取出新的 slice。 这里 data 可以是数组或者 slice。 low 是最低索引值,这里是闭区间,也就是说第一个元素是 data 位于 low 索引处的元素;而 high 和 max 则是开区间, 表示最后一个元素只能是索引 high - 1 处的元素,而最大容量则只能是索引 max - 1 处的元素。
要求: max >= high >= low
当 high == low 时,新 slice 为空。high 和 max 必须在老数组或者老 slice 的 容量(cap) 范围内。
运行一下代码,输出的是什么?
func main() {
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:6:7]
s2 = append(s2, 10)
s2 = append(s2, 11)
s1[2] = 12
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(slice)
}
2
3
4
5
6
7
8
9
10
11
运行后得到以下输出
[2 3 12]
[4 5 6 7 10 11]
[0 1 2 3 12 5 6 7 10 9]
2
3
得到这样结果的原因是:
s1从slice索引2(闭区间)到索引5(开区间,元素真正取到索引为4),长度为3,容量默认到数组结尾,cap=8s2从s1索引2(闭区间)到索引6(开区间,元素真正取到索引为5),容量到索引 ``7(开区间,元素真正取到索引为6),cap=5`
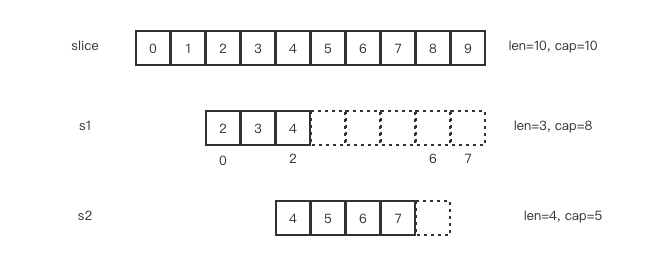
slice、s1、s2三者的元素指向同一个底层数组。
向 s2 尾部追加一个元素 10
s2 = append(s2, 10)
此时,s2 的容量刚好够,直接追加。
这会修改原始数组对应位置的元素
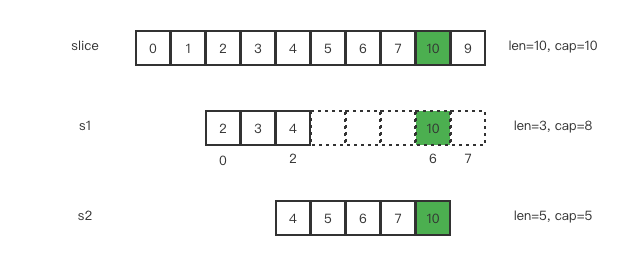
再次向 s2 追加元素 11
s2 = append(s2, 11)
此时,s2 的容量不够用,需要进行扩容,于是 s2 从新生成底层数组,将原来的元素复制到新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容, s2 会在此次扩容的时候多留一些 buffer,新的容量将扩大为原始容量的 2倍,也就是 10。
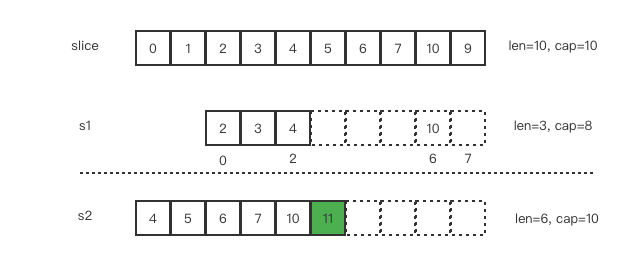
此时,
s2的底层数组元素和slice、s1已经没有任何关系
最后修改 s1 索引为 2 位置的元素
s1[2] = 12
![s1[2]=12](/img/202205181214878.png)
# 切片的容量是怎么增长的
一般都是在向切片追加元素之后,由于容量不足,才会引起扩容。向切片追加元素调用的是 append 函数。append 函数的原型如下
// gosrc/builtin/builtin.go line:134
func append(slice []Type, elems ...Type) []Type
2
append函数是返回值是一个新的切片,Go 语言的编译器不允许调用 append 函数后不使用返回值。所以下面的用法是错误的,不能通过编译
append(slice, elem1, elem2)
append(slice, slices...)
2
使用 append 函数可以向 slice追加元素,实际上是往底层数组相应的位置放置要追加的元素。但是底层数组的长度是固定的,如果索引 len - 1所指向的元素已是底层数组的最后一个元素,那就不能在继续放置新的元素了。
这时,slice 会整体迁移到新的位置,并且底层数组的长度也会增加,使得可以继续放置新的元素。同时,为了应对未来可能再次发生的 append操作,新的底层数组的长度,也就 slice 的容量需要预留一定的 buffer。否则每次添加新的元素的时候,都会发生迁移,成本过高。
新 slice 预留一定的 buffer 大小是有一些规律的。
网络上流传的规律是
- 当原
slice容量小于1024的时候,新slice的容量变成原来的2倍 - 当原
slice容量大于1024的时候,新slice的容量变成原来的1.25倍
为了验证切片的扩容规律,首先我们通过下面程序来验证下扩容的行为
func main() {
s := make([]int, 0)
oldCap := cap(s)
for i := 0; i < 2048; i++ {
s = append(s, i)
newCap := cap(s)
if newCap != oldCap {
fmt.Printf("[%d -> %4d] cap = %-4d | after append %-4d cap = %-4d\n", 0, i-1, oldCap, i, newCap)
oldCap = newCap
}
}
}
2
3
4
5
6
7
8
9
10
11
12
代码运行结果如下
[0 -> -1] cap = 0 | after append 0 cap = 1
[0 -> 0] cap = 1 | after append 1 cap = 2
[0 -> 1] cap = 2 | after append 2 cap = 4
[0 -> 3] cap = 4 | after append 4 cap = 8
[0 -> 7] cap = 8 | after append 8 cap = 16
[0 -> 15] cap = 16 | after append 16 cap = 32
[0 -> 31] cap = 32 | after append 32 cap = 64
[0 -> 63] cap = 64 | after append 64 cap = 128
[0 -> 127] cap = 128 | after append 128 cap = 256
[0 -> 255] cap = 256 | after append 256 cap = 512
[0 -> 511] cap = 512 | after append 512 cap = 1024
[0 -> 1023] cap = 1024 | after append 1024 cap = 1280
[0 -> 1279] cap = 1280 | after append 1280 cap = 1696
[0 -> 1695] cap = 1696 | after append 1696 cap = 2304
2
3
4
5
6
7
8
9
10
11
12
13
14
当老 s 容量小于 1024 的时候,新 s 的容量确实是老 s 的 2 倍,目前还算准确。
但当老 s 的容量大于等于 1024 的时候, 情况有了变化。
[0 -> 1279] cap = 1280 | after append 1280 cap = 1696
[0 -> 1695] cap = 1696 | after append 1696 cap = 2304
2
- 1696/1280 = 1.325
- 2304/1696 = 1.358
由上我们发现 当原 slice 容量大于 1024 的时候,新 slice 的容量变成原来的 1.25 倍并不正确。
我们使用 go tool compile 工具添加 -S 参数来查看汇编代码
go tool compile -S main.go
从实际的汇编代码能就看到, 向 s 追加元素的时候, 若容量不够,会调用 growslice 函数。
// gosrc/runtime/slice.go line: 125
func growslice(et *_type, old slice, cap int) slice {
// ...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
//...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
如果只看前半部分,现在 网络上流传的扩容规律 就是对的。 现实是,代码的后半部分还对 newcap 进行了内存对齐,而这个和内存的分配策略相关。进行内存对其之后,新 s 的容量要大于老 s 容量的 2 倍或者 1.25 倍。