Go 泛型浅析
泛型程序设计(generic programming)是程序设计语言的一种风格或范式。泛型允许程序员在强类型程序设计语言中编写代码时使用一些以后才指定的类型,在实例化时作为参数指明这些类型。
各种程序设计语言和其编译器、运行环境对泛型的支持均不一样。Ada、Delphi、Eiffel、Java、C#、F#、Swift和Visual Basic .NET称之为泛型(generics);ML、Scala和Haskell称之为参数多态(parametric polymorphism);C++和D称之为模板。具有广泛影响的1994年版的《Design Patterns》一书称之为参数化类型(parameterized type)。
直白一点来说,就是允许我们基于一个还不确定的类型展开程序设计,我们围绕该类型编写代码逻辑时,它可能还未被定义出来。我们通常需要假设它具有某些属性,或者支持某些操作。所以泛型编程面向的是具有某些共同特性的一组类型,比起普通的面向对象编程,是一种更高层次的抽象。
Go语言 在Go1.17版已经支持泛型尝鲜,Go1.18正式支持泛型。我们为什么如此的期待泛型呢?因为我们期待泛型能够解决现阶段的一些痛点。
本文中所有代码是在
Go1.18.5上实验的
# 目前有什么痛点呢?
我们的代码中经常会用到一些本地缓存组件, 有的支持过期时间, 有的基于 LRU 算法. 这些都是复用性极高的基础组件,经常以 package形式提供. 例如
这些组件在使用体验上都跟map差不多,都提供了Set和Get这类方法。为了支持任意类型,这些方法都使用了interface{}类型的参数。经过简化之后,其核心结构就是如下这种形式:
type Cache map[string]interface{}
func (c Cache) Set(k string, v interface{}) {
c[k] = v
}
func (c Cache) Get(k string) (interface{}, bool) {
v, ok := c[k]
return v, ok
}
2
3
4
5
6
7
8
9
10
内部实际存储数据的就是个值类型为interface{}的map,interface{}是个万能容器,可以装载任意类型。
使用 Set方法的时候, 一般不会觉得有什么不方便,因为从具体类型或接口到 interface{} 的赋值不需要进行额外处理
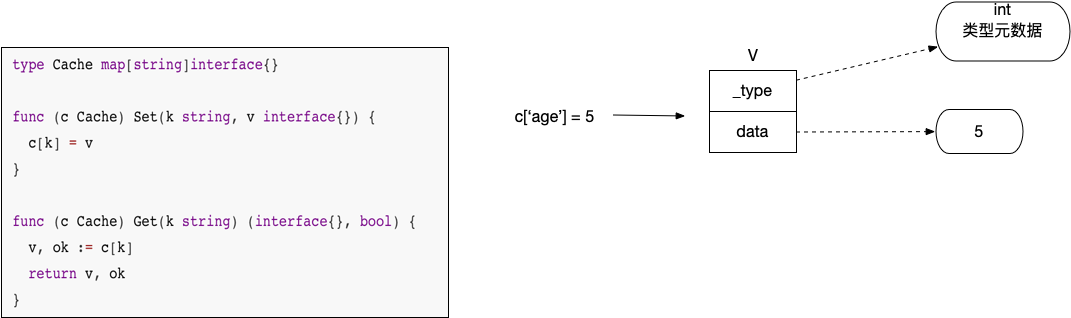
但是Get方法使用起来就不那么完美了,我们需要通过类型断言把取出来的数据转换成预期的类型。比如我想从本地缓存c里面取出来一个int,那就需要这样来写代码:
if v, ok := c.Get("key"); ok {
if s, ok := v.(int); ok {
// use s
}
}
2
3
4
5
多了一步类型断言操作。如果你能够保证缓存里的值只有int这一种类型的话,也可以不使用comma ok风格的断言,这样更简单一点:
s := v.(int)
如果仅仅是多这一步操作的话,我们也就忍了,实际上可不是这么简单。
interface{}本质上是一对指针,用来装载值类型时会发生装箱,造成变量逃逸
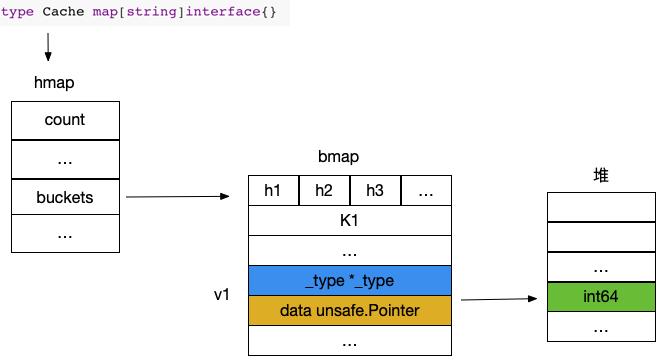
我们用上面的 Cache 来缓存 int64 类型, map 的 bucket 里存储的是一个一个的interface{},而实际的int64 会在堆上单独分配, interface{} 上面的数据指针指向堆上的 int64
而最高效的存储结构是直接把int64存储在map的bucket里
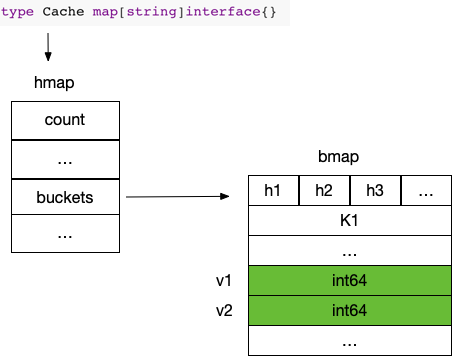
对比之下,基于 interface{} 的存储方式凭空多出来一次堆分配,并且又多占用了两倍的内存空间。从性能方面来考虑的话,这绝对是个十足的痛点了,我们期待泛型能够解决这个问题。
# Go泛型如何使用?
之前关于Type Parameters 的 Draft ,现在已经升格为 Type Parameters Proposal (opens new window)
# 1. 类型参数
类型参数 就是 参数化类型的那个参数 ,直到使用的时候才被明确出来。
比如如下代码中的类型T,就是个类型参数:
func printAll[T any](s ...T) {
for _, v := range s {
fmt.Println(v)
}
}
2
3
4
5
实际调用 printAll 函数的时候,可以明确指定类型参数
printAll[int](1, 2, 3)
也可以省略掉类型参数,编译器可以根据上下文进行推导
printAll(1, 2, 3)
# 2. 约束
前面我们说过,泛型编程是抽象的,通常是面向具有某些相同属性、或者支持某些相同操作的一组类型。
在Go这种强类型语言中,我们希望可以根据这些来对类型参数进行约束。
之前就已经有了接口这种组件,用来定义类型支持的一组操作,所以泛型这里就直接复用了接口来描述约束条件。
上面printAll函数的类型参数T后面的any就是约束,但是any比较特殊,可以把它理解成不进行任何约束。
还是针对上面的 printAll 函数,假如我们希望传入的类型 T 实现 String() 方法,可以这样进行约束
func printAll[T fmt.Stringer](s ...T) {
for _, v := range s {
fmt.Println(v.String())
}
}
2
3
4
5
这里的
fmt.Stringer接口只是被用作约束条件,编译阶段供编译器进行检查,并不会用到接口的动态派发等运行时特性。
# 3. 类型集
有时候只通过方法来约束是不够的,比如对于语言内置的各种整型类型,它们是没有任何方法的,但是它们都支持整数运算。所以泛型实现的时候,又对接口的语法进行了扩展,可以使用如下语法根据已有类型来定义一个类型集
type Integer interface {
int | int8 | int16 | int32 | int64 | uint | uint8 | uint16 | uint32 | uint64 | uintptr
}
2
3
上述代码根据Go里面所有的整型类型定义了一个 Integer 类型集,该类型集也可以被用作约束
func add[T Integer](a, b T) T {
return a + b
}
2
3
上述的约束集, 在自定义数据类型将会报错
type Integer interface {
int | int8 | int16 | int32 | int64 | uint | uint8 | uint16 | uint32 | uint64 | uintptr
}
func add[T Integer](a, b T) T {
return a + b
}
type MyInt int
func main() {
fmt.Println(add(MyInt(1), MyInt(2)))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
假如我们想让 add 方法支持自定义类型, 一种是在约束条件上添加 自定义类型MyInt 的约束
type Integer interface {
int | int8 | int16 | int32 | int64 | uint | uint8 | uint16 | uint32 | uint64 | uintptr | MyInt
}
2
3
这种方法在确定自定义类型的个数的时候,确实可以支持, 但是我们想让 所有自定义 int 类型都在约束集的范围内, 可以使用 ~int
~int 表示所有底层数据都是 int 都支持
type Integer interface {
~int | int8 | int16 | int32 | int64 | uint | uint8 | uint16 | uint32 | uint64 | uintptr
}
func add[T Integer](a, b T) T {
return a + b
}
type MyInt int
func main() {
fmt.Println(add(MyInt(1), MyInt(2)))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
编译正常,输入 3
编译器就可以根据该类型集支持的操作,对函数代码的合法性进行检查。
# 4. 泛型类型
所谓 泛型类型 ,指的就是包含类型参数的复合类型。比如我们可以用切片加上类型参数,来模拟C++标准库中的 vector 类型
type vector[T any] []T
还可以为它定义方法,比如实现一个向 vector 中追加元素的 pushBack 方法
func (v *vector[T]) pushBack(e T) {
*v = append(*v, e)
}
2
3
关于泛型的基本用法就介绍到这里,大家感兴趣的话可以自行阅读 Type Parameters Proposal (opens new window)。
# 基于泛型实现的缓存是什么样子的?
我们基于 Go1.18 中的泛型实现来改造一下上面的缓存类
package cache
type Cache[T any] map[string]T
func (c Cache[T]) Set(k string, v T) {
c[k] = v
}
func (c Cache[T]) Get(k string) (v T, ok bool) {
v, ok = c[k]
return
}
2
3
4
5
6
7
8
9
10
11
12
我们可以像如下代码这样使用改造过的泛型缓存类
var c cache.Cache[int64]
func main() {
c = make(cache.Cache[int64])
c.Set("nine", 9)
if n, ok := c.Get("nine"); ok {
println(n)
}
}
2
3
4
5
6
7
8
9
为了方便进一步分析研究,我们构建可执行文件的时候使用如下命令关闭编译器的内联优化
go build -gcflags='-l'
然后使用 nm 命令来分析可执行文件, 可以看到编译器为 cache[int64] 类型生成的两个方法
go tool nm `编译的文件` | grep cache.\Cache

# 有了泛型还需要 interface{} 吗?
泛型并不会替代 interface{} ,其实两者的适用场景根本不同。泛型本质上是编译阶段的代码生成,而 interface{} 主要用来实现语言的动态特性。
针对上面的 cache 类型来讲,如果你希望在一个缓存对象里存放多种不同类型的值,你还是需要 interface{}
var c cache[interface{}]
# 会不会为每个类型生成一套代码
实践是检验真理的唯一标准,所以我们就实际写个泛型函数来验证一下。如下代码给出了一个只有一个类型参数的泛型函数,并且分别用两种类型参数来调用它:
import (
"fmt"
)
func Print[T any](v T) {
fmt.Printf("%T: %[1]v\n", v)
}
type Int int
func main() {
Print(1)
Print(Int(2))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
首先来看一下运行效果,使用 go1.18 进行编译,然后运行得到的可执行文件,输出结果如下所示:
go build -gcflags='-l
./{编译生成的二进制文件}
2

接下来我会查看一下可执行文件的main包中都有什么东西
go tool nm {编译生成的二进制文件} | grep ' main\.'

除了main函数之外,数据段中的这个 inittask 是包依赖初始化要用的数据结构。
值得注意的是Print函数,并没有像我们猜想的那样生成两套代码。我们原本以为应该生成一个 main.Print[int] 函数和一个 main.Print[main.Int] 函数,但是却只发现了一个 main.Print[go.shape.int_0] 函数,而且函数名字还这么奇怪。在只读数据段里有两个dict,看起来跟 Print 函数也有些关系。为了弄清楚它们之间的关系,我们反编译一下 main 函数,调用 Print 函数的两段汇编代码如下所示
go build -gcflags -S

// Print(1)
LEAQ ""..dict.Print[int](SB), AX
MOVL $1, BX
PCDATA $1, $0
CALL "".Print[go.shape.int_0](SB)
// Print(Int(2))
LEAQ ""..dict.Print["".Int](SB), AX
MOVL $2, BX
CALL "".Print[go.shape.int_0](SB)
2
3
4
5
6
7
8
9
10
11
我们可以看到,这两次调用的都是 main.Print[go.shape.int_0] 这个函数。
通过新版调用约定的寄存器传参规则,可以反推出来,这个函数有两个参数,第一个是个dict的地址,第二个应该是个整型参数。
这两次调用分别使用了不同的dict,说明这个dict和实际的类型参数相关。进行到这里出现了很多新东西,为了提高后续探索研究的效率,我们需要先理解相关的设计思想。
# Proposal
Type Parameters Proposal (opens new window)描述了go1.18中如何基于 字典 和 gcshape 模板来实现泛型。编译器实现泛型侧重于创建泛型函数和方法的实例,这些函数和方法将使用具体的类型参数来执行。为了避免为具有不同类型参数的每次函数或方法调用都生成一个实例(也就是纯模板),我们在每次泛型函数或方法的调用中都会传递一个字典。在字典里提供了有关类型参数的信息,这样就可以用一个实例支持多种不同的类型参数。
(注:设计者认为纯模板方式会造成代码量暴增,进而影响CPU指令缓存和分支预测的性能)
出于实现起来更简单以及性能方面的考量,我们没有用一个实例来支持所有可能的类型参数。相反,我们让具有相同 gcshape 的一组类型参数共享一个实例。
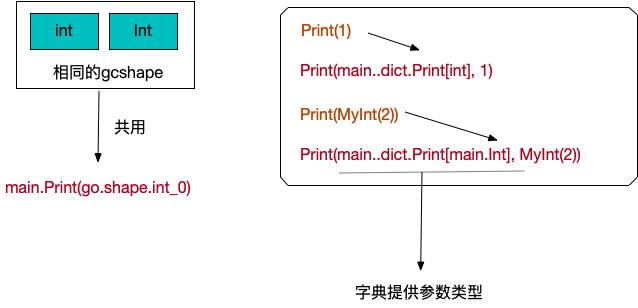
gcshape 代表了一组类型,单从名字来看似乎和 GC 有关,你可能会想到内存布局中的标量和指针,事实上还要更严格一些。在目前的实现中,如果两个类型有着同样的底层类型,或者它们都是指针类型,那么他们就属于同一个gcshape。
这样设计的好处是,不需要在字典中包含运算符方法(例如,对于不同宽度的整型,加法运算符+ 对应的机器指令也不太一样)。同样,一个 gcshape 中的所有类型始终以相同的方式实现内置方法(例如make、new和 len)。接口类型和非接口类型属于不同的gcshape ,即使非接口类型有着和接口相同的双指针结构,因为在调用方法时它们的行为差异很大。
在命名方面,所有的 gcshape 都会被放置到内置包 go.shape 中。
由于实现方面的原因,我们根据类型参数在列表出现的顺序,为相应的 gcshape 类型加上序号后缀。
因此,当一个底层是 string 类型的类型参数出现在列表中第一个位置时,就会被命名为 go.shape.string_0,出现在第二个位置时就会被命名为go.shape.string_1 ,以此类推。所有的指针类型都作为 uint8 类型来命名,也就是 go.shape.*uint8_0 以及 go.shape.*uint8_1 等。
我们把一个泛型函数或方法针对一组shape类型参数的实例化,称为shape实例化。
# 字典格式
字典是在编译阶段静态确定的,与泛型函数或方法的调用以及调用时具体的类型实参相对应。调用一个函数或方法需要传递对应的字典,字典根据被调用的泛型函数或方法的完全限定名称和具体的类型参数来命名,比如上面的 main..dict.Print[int] 和 main..dict.Print[main.Int] 。
字典中包含了调用一个泛型函数或方法的 shape 实例所需的具体类型参数信息,有着相同名字的字典会被编译器和链接器去重。
为了创建所需的字典,我们需要把 shape 类型参数替换为真正的类型参数,这就要求 shape 类型参数完全可区分。类型参数列表中可能有多个shape 参数有着相同的类型,所以我们才要按照它们的顺序给它们加上编号后缀,这样就确保了不同 shape 参数间完全可区分。
接下来我们就一边参照 Type Parameters Proposal (opens new window)一边实践,来看一下字典中到底包含哪些内容。go1.18的编译器在开发的时候,内置了打印字典相关调试信息的代码,只不过在发布的时候用一个布尔变量把这部分逻辑关闭掉了,我们可以再把它打开。在 src/cmd/compile/internal/noder/stencil.go 的第32行有个infoPrintMode 变量,它的默认值是 false ,把它改成 true,然后执行src 下的 buildall.bash 来重新构建编译器。用构建好的编译器来编译泛型代码,就能够看到生成了哪些字典,以及各个字典的结构。下面,我们实际看一下组成字典的4大部分:
# 1. 具体类型参数
这一区间包含了用来调用泛型函数或方法的类型参数的类型信息,也就是对应的runtime._type的地址。比如,build如下代码:
package main
import (
"fmt"
)
func Print[T any](v T) {
fmt.Printf("%T: %[1]v\n", v)
}
type Int int
func main() {
Print(Int(2))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
编译器输出的调试信息如下所示:
$ go build main.go
# command-line-arguments
>>> InstInfo for Print[go.shape.int_0]
Typeparam go.shape.int_0
>>> Done Instinfo
=== Creating dictionary .dict.Print["".Int]
* Int
Main dictionary in main at generic function call: Print - (<node FUNCINST>)(Int(2))
=== Finalizing dictionary .dict.Print["".Int]
=== Finalized dictionary .dict.Print["".Int]
2
3
4
5
6
7
8
9
10
函数 Print[go.shape.int_0] 有一个 shape类型 参数 go.shape.int_0 ,后缀 0 表明这是第一个类型参数。在创建字典 .dict.Print["".Int] 的时候,只包含了一项,也就是 Int类型 的类型元数据地址。有兴趣的话,可以反编译一下 main.Print[go.shape.int_0] 这个函数,你会发现 fmt.Printf 之所以能够打印出类型的名称,就是因为这个字典传递了对应的类型元数据信息。
# 2. 派生类型信息
这种情况所描述的,就是泛型函数或方法中基于类型参数创建了新的类型,比如 *T、 []T和 map[K,V]等,并且我们需要用到这些派生类型的动态类型信息(类型元数据)。比如显式或隐式的转换为空接口类型 interface{},或者作为 type switch 或类型断言的目标类型等。简单起见,我们就来测试一个 []T 的示例,对上一段代码稍作修改,只是改动了 fmt.Printf 的第二个参数:
func Print[T any](v T) {
fmt.Printf("%T: %[1]v\n", []T{v})
}
2
3
再次编译输出的调试信息如下:
$ go build main.go
# command-line-arguments
>>> InstInfo for Print[go.shape.int_0]
Typeparam go.shape.int_0
Derived type []go.shape.int_0
>>> Done Instinfo
=== Creating dictionary .dict.Print["".Int]
* Int
- []Int
Main dictionary in main at generic function call: Print - (<node FUNCINST>)(Int(2))
=== Finalizing dictionary .dict.Print["".Int]
=== Finalized dictionary .dict.Print["".Int]
2
3
4
5
6
7
8
9
10
11
12
13
明显看到 Print[go.shape.int_0] 函数多出来一个派生的shape类型参数,字典中也相应的包含了 []Int 对应的类型信息,实际上也是类型元数据的地址。这个例子说明,连派生类型的类型信息都是要由调用者来准备好。
# 3. 子字典区间
所谓子字典 sub-dictionaries ,也就是当前这个泛型函数或方法又调用其他泛型函数或方法时,这些子调用所需要传递的字典。没错,这也是需要从外层一起生成并传递进来的。我们重写一下上面的例子,加上嵌套的泛型函数调用:
package main
import (
"fmt"
)
func Print[T any](v T) {
fmt.Printf("%T: %[1]v\n", v)
}
func PrintSlice[T any](s []T) {
for i := 0; i < len(s); i++ {
Print(s[i])
}
}
type Int int
func main() {
PrintSlice([]Int{1, 2})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
这次编译后输出的调试信息如下所示:
$ go build main.go
# command-line-arguments
>>> InstInfo for PrintSlice[go.shape.int_0]
Typeparam go.shape.int_0
Subdictionary at generic function/method call: Print - (<node FUNCINST>)(s[i])
Derived type []go.shape.int_0
Derived type func(go.shape.int_0)
>>> Done Instinfo
=== Creating dictionary .dict.PrintSlice["".Int]
* Int
- []Int
- func(Int)
=== Creating dictionary .dict.Print["".Int]
* Int
>>> InstInfo for Print[go.shape.int_0]
Typeparam go.shape.int_0
>>> Done Instinfo
- Subdict .dict.Print["".Int]
Main dictionary in main at generic function call: PrintSlice - (<node FUNCINST>)([]Int{...})
Sub-dictionary in PrintSlice[go.shape.int_0] at generic function call: Print - (<node FUNCINST>)(s[i])
=== Finalizing dictionary .dict.Print["".Int]
=== Finalized dictionary .dict.Print["".Int]
=== Finalizing dictionary .dict.PrintSlice["".Int]
=== Finalized dictionary .dict.PrintSlice["".Int]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
先来看看函数 PrintSlice[go.shape.int_0] 的实例化信息,除了我们意料之中的 subdictionary 和派生类型 []go.shape.int_0,连它调用的另一个泛型函数也有一个派生类型 func(go.shape.int_0) 与之对应。字典 .dict.PrintSlice["".Int] 中包含了一个类型参数信息,两个派生类型信息,还有一个子字典。子字典的结构比较简单,我们就不再展开说明了。
# 4. itab区间
存在这个区间主要是因为,我们的泛型函数或方法中,可能会存在从类型参数以及其派生类型到一种非空接口类型的转换,或者从一个非空接口到类型参数及其派生类型的类型断言等。这种情况下就需要用到相应itab的地址,这也要从外层准备好并传递给被调用的泛型函数或方法,后者从字典中取出并使用。为了展示这种情况,我们再修改一下上面的例子:
package main
import (
"fmt"
"strconv"
)
func Print[T fmt.Stringer](v T) {
fmt.Printf("%T: %[1]v\n", v.String())
}
func PrintSlice[T fmt.Stringer](s []T) {
for i := 0; i < len(s); i++ {
Print(s[i])
}
}
type Int int
func (n Int) String() string {
return strconv.Itoa(int(n))
}
func main() {
PrintSlice([]Int{1, 2})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
我们把两个泛型函数中类型参数的约束条件都改成了 fmt.Stringer 接口,这就让我们可以在 Print函数 中调用 v 的 String 方法。注意,必须要用代码显式调用,这样才是泛型,被 fmt.Printf 隐式调用的话,那是接口的动态派发。编译上述代码,得到的调试输出如下所示:
$ go build main.go
# command-line-arguments
>>> InstInfo for PrintSlice[go.shape.int_0]
Typeparam go.shape.int_0
Subdictionary at generic function/method call: Print - (<node FUNCINST>)(s[i])
Derived type []go.shape.int_0
Derived type func(go.shape.int_0)
>>> Done Instinfo
=== Creating dictionary .dict.PrintSlice["".Int]
* Int
- []Int
- func(Int)
=== Creating dictionary .dict.Print["".Int]
* Int
>>> InstInfo for Print[go.shape.int_0]
Typeparam go.shape.int_0
Optional subdictionary at generic bound call: v.String()
Itab for bound call: v.String
>>> Done Instinfo
- Unused subdict entry
- Subdict .dict.Print["".Int]
Main dictionary in main at generic function call: PrintSlice - (<node FUNCINST>)([]Int{...})
Sub-dictionary in PrintSlice[go.shape.int_0] at generic function call: Print - (<node FUNCINST>)(s[i])
=== Finalizing dictionary .dict.Print["".Int]
+ Itab for (Int,fmt.Stringer)
=== Finalized dictionary .dict.Print["".Int]
=== Finalizing dictionary .dict.PrintSlice["".Int]
=== Finalized dictionary .dict.PrintSlice["".Int]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
与上个例子相比,字典 .dict.PrintSlice["".Int] 的结构没什么变化,但是子字典 .dict.Print["".Int] 中增加了一个对应 (Int,fmt.Stringer) 的itab。如果反编译一下函数 Print[go.shape.int_0],你会发现调用 v 的 String 方法时,是从字典中的 itab 里取得的方法地址。至于接收者,是在栈上分配的一个副本,实际传递了这个副本的地址。

Go把拥有相同底层类型的所有类型归为一组,并让它们共享同一个函数或方法实例(机器码层面),为了让这个共享的实例中能够区分实际的参数类型,就通过字典的形式把类型信息传进去。